This page provides a curated overview of my research journey, highlighting a diverse portfolio of projects developed over the past two decades.
Introduction
My research spans smart cities, healthcare, assistive technologies, and music information retrieval — all aimed at the same goal: getting machines to better perceive and interpret sound in the real world. Across these projects I keep coming back to the same threads: careful data collection and curation, robust evaluation methodologies, getting systems actually deployed, and working across disciplines and communities in machine listening.
Research Journey
The timeline below traces the past two decades of my research, from early work in music information retrieval to international initiatives on smart-city audio analytics and acoustic scene understanding.
Understanding - : done, 2023-09-01, 2025-08-31 section Audio Content
Analysis Smart Cities: done, 2021-08-01, 2023-12-30 Everyday Environments : done, 2015-06-01, 2020-06-30 %% Interactive Learning : done, 2014-09-01, 2015-12-31 Assistive : done, 2014-05-01, 2016-12-31 Groundwork : done, 2009-01-01, 2013-06-01 section Acoustic
Monitoring Healthcare : done,2017-09-01, 2020-08-31 Noise : done, 2018-03-01,2020-03-31 Noise : done, 2013-01-01,2015-04-30 section Music
Information
Retrieval Instruments : done, 2006-04-01, 2008-12-31 Genre : done, 2002-01-01,2003-12-31 section Electroacoustics Loudspeaker Modeling : done, 2004-01-01, 2006-03-31 %% section Supervision &
Advisory Roles %% Zero-Shot Learning: active, 2022-06-01, 2025-09-01 %% Spkr Distortions : active, 2024-06-01, 2025-05-31 %% Captioning : active, 2022-08-01, 2023-09-30 %% Active Learning : active, 2017-01-01, 2022-01-19 %% Traffic Mon. : active,2018-05-01,2019-08-31 %% Semi-Supervised Learning: active, 2012-06-01, 2013-10-31 %% Guitar Transcription: active,2011-05-01,2011-12-31 %% Spkr Modeling : active, 2006-04-01, 2010-03-31 %% section %% Msc : milestone, 2003-02-14, 0d %% Phd : milestone, 2021-06-18, 0d
I am also actively involved in guiding students at various stages of their academic journey.
See page about my advisory involvement
Acoustic Scene Understanding
Funded by a personal grant from the Tampere Institute for Advanced Study, this project develops a multi-tiered audio analysis framework for acoustic scene understanding — aiming to automatically extract contextual meaning from everyday sounds.
You can find an introduction video to the project below:
Audio Content Analysis in Everyday Environments
Understanding everyday sounds is the core of audio content analysis. I build systems that recognize, categorize, and explain sound events in busy real-world environments — for smart cities, healthcare, assistive technologies, and environmental monitoring — using machine learning, audio signal processing, and large-scale data to make technology more responsive to the sounds around it.
Audio Analytics for Smart Cities

MARVEL (Multimodal Extreme Scale Data Analytics for Smart Cities Environments) was an EU-funded Horizon 2020 project with 17 partners across 12 countries, building an Edge-Fog-Cloud framework to help smart city authorities put AI and high-performance computing to practical use. The goal was real-time, privacy-aware, context-sensitive analytics of multimodal audio-visual data — covering situational awareness, public safety, urban mobility, and citizen engagement.
I managed Tampere University's participation in the consortium (project manager, work package leader, task leader, standardization manager) and led the research on environmental sound classification and tagging, sound event detection, and automatic audio captioning for smart city applications — adapting academic methods to real use cases like vehicle detection, human action recognition, and hazardous sound detection.
I built and optimized the sound recognition pipelines for real-time use and deployed them as containerized services within the project's monitoring infrastructure. Alongside the technical work, I mentored research assistants and supervised a Master's thesis on the requirements and implementation of automatic audio captioning within that infrastructure.
- Leadership in project coordination: Served as project manager for Tampere University's involvement in the MARVEL consortium.
- Advanced audio analysis modules: Delivered audio content analysis components for real-world smart city applications.
- Unified audio analytics component: Developed a versatile component for environmental audio analysis tasks within the MARVEL infrastructure. Application-specific configurations are set at deployment within a Kubernetes environment, with AI models dynamically loaded from a MinIO-based model repository. The component integrates into the MARVEL system via MQTT messaging using RabbitMQ.
Siniša Suzić, Irene Martín-Morató, Nikola Simić, Charitha Raghavaraju, Toni Heittola, Vuk Stanojev, and Dragana Bajović. UNS exterior spatial sound events dataset for urban monitoring. In 2024 32th European Signal Processing Conference (EUSIPCO), volume, 176–180. 2024. 1 cite
UNS Exterior Spatial Sound Events dataset for urban monitoring
Abstract
This paper presents the UNS-Exterior Spatial Sound Events 2023 (UNS-ESSE2023) dataset, which is targeted for applications related to monitoring urban environments. The dataset comprises spatial recordings collected outdoors in real acoustic environments by playing ambience and target sound samples with eight speakers placed circularly around the microphone array. The target sound events are three anomaly sounds (gunshot, boom (explosion), and shatter), specifically selected as examples of unexpected sound events in the context of monitoring urban spaces. The dataset is evaluated using the sound event detection and localization baseline system from the DCASE2023 challenge. The model was fine-tuned for the dataset to introduce a benchmark for sound event localization and detection in exterior acoustic environments. Comparisons are also made with similar outcomes from the STARS22 dataset, a reference dataset for the SELD task in interior conditions. Results are presented using information about the different levels of signal-to-noise ratio and ambience sound pressure levels, showcasing the complexity of the dataset.
Cites: 1 (see at Google Scholar)
Charitha Raghavaraju. Enhancing domain-specific automated audio captioning: a study on adaptation techniques and transfer learning. Master's thesis, Tampere University, Finland, 2023.
Enhancing Domain-Specific Automated Audio Captioning: a Study on Adaptation Techniques and Transfer Learning
Abstract
Automated audio captioning is a challenging cross-modal task that takes an audio sample as input to analyze it and generate its caption in natural language as output. The existing datasets for audio captioning such as AudioCaps and Clotho encompass a diverse range of domains, with current proposed systems primarily focusing on generic audio captioning. This thesis delves into the adaptation of generic audio captioning systems to domain-specific contexts, simultaneously aiming to enhance generic audio captioning performance. The adaptation of the generic models to specific domains has been explored using two different techniques: complete fine-tuning of neural model layers and layer-wise fine-tuning within transformers. The process involves initial training with a generic captioning setup, followed by adaptation using domain-specific training data. In generic captioning, the process for training starts with training the model on the AudioCaps dataset followed by fine-tuning it using the Clotho dataset. This is accomplished through the utilization of a transformer-based architecture, which integrates a patchout fast spectrogram transformer (PaSST) for audio embeddings and a BART transformer. Word embeddings are generated using a byte-pair encoding (BPE) tokenizer tailored to the training datasets’ unique words, aligning the vocabulary with the generic captioning task. Experimental adaptation mainly focuses on audio clips related to animals and vehicles. The results demonstrate notable improvements in the performance of the generic and domain adaptation systems. Generic captioning has demonstrated an improvement in SPIDEr scores, increasing from 0.291 during fine-tuning to 0.301 with layer-wise fine-tuning. Specifically, we observed a notable increase in SPIDEr scores, from 0.315 to 0.323 for animal-related audio clips and from 0.298 to 0.308 for vehicle-related audio clips.
Alexandros Iosifidis. MARVEL D3.5 - multimodal and privacy-aware audio-visual intelligence – final version. July 2023. URL: https://doi.org/10.5281/zenodo.8147164, doi:10.5281/zenodo.8147164.
MARVEL D3.5 - Multimodal and privacy-aware audio-visual intelligence – final version
Abstract
This document describes methodologies proposed by MARVEL partners during the second reporting period of the project towards the realisation of the Au- dio, Visual and Multimodal AI Subsystem of the MARVEL architecture. These meth- odologies complement the methodologies proposed by MARVEL partners during the first reporting period, and include methods for Automated Audio Captioning, Visual Crowd Counting, Visual Anomaly Detection, Audio-Visual Anomaly Detection, Audio- Visual Event Detection, privacy-preserving Audio-Visual Emotion Recognition, as well as methodologies for improving the training of dense regression models for efficient inference on standard and Gigapixel images, and on heavily compressed images. The effectiveness of these methods is compared against recent baselines, towards achieving the AI methodology-related objectives of the MARVEL project.
Irene Martín-Morató, Francesco Paissan, Alberto Ancilotto, Toni Heittola, Annamaria Mesaros, Elisabetta Farella, Alessio Brutti, and Tuomas Virtanen. Low-complexity acoustic scene classification in dcase 2022 challenge. In Proceedings of the 7th Detection and Classification of Acoustic Scenes and Events 2022 Workshop (DCASE2022). Nancy, France, November 2022. 61 cites
Low-Complexity Acoustic Scene Classification in DCASE 2022 Challenge
Abstract
This paper presents an analysis of the Low-Complexity Acoustic Scene Classification task in DCASE 2022 Challenge. The task was a continuation from the previous years, but the low-complexity requirements were changed to the following: the maximum number of allowed parameters, including the zero-valued ones, was 128 K, with parameters being represented using INT8 numerical format; and the maximum number of multiply-accumulate operations at inference time was 30 million. Despite using the same previous year dataset, the audio samples have been shortened to 1 second instead of 10 second for this year challenge. The provided baseline system is a convolutional neural network which employs post-training quantization of parameters, resulting in 46.5 K parameters, and 29.23 million multiply-and-accumulate operations (MMACs). Its performance on the evaluation data is 44.2% accuracy and 1.532 log-loss. In comparison, the top system in the challenge obtained an accuracy of 59.6% and a log loss of 1.091, having 121 K parameters and 28 MMACs. The task received 48 submissions from 19 different teams, most of which outperformed the baseline system.
Cites: 61 (see at Google Scholar)
Christos Dimou. MARVEL - D5.1: marvel minimum viable product. January 2022. URL: https://doi.org/10.5281/zenodo.7543692, doi:10.5281/zenodo.7543692.
MARVEL - D5.1: MARVEL Minimum Viable Product
Abstract
The purpose of this deliverable is to describe all activities related to the design, implementation, and release of the MARVEL Minimum Viable Product (MVP). This document sets the scope and goals of the MVP, as well as discusses the decisions to achieve these goals, by means of definition of specific use case scenarios, selection of MARVEL components, and infrastructure that facilitates the operation and demonstration of the use cases. More specifically, the document details the adjustments of the MARVEL architecture, the specific role of each component within the MVP, integration and deployment processes and tasks, and an extensive demonstration of the selected use cases from the user point of view. Finally, the MVP results are linked to MARVEL’s objectives, as this release paves the way towards the first complete prototype of the MARVEL framework.
Toni Heittola and Tuomas Virtanen. MARVEL - D5.2: technical evaluation and progress against benchmarks – initial version. February 2022. URL: https://doi.org/10.5281/zenodo.7543693, doi:10.5281/zenodo.7543693.
MARVEL - D5.2: Technical evaluation and progress against benchmarks – initial version
Abstract
The purpose of this deliverable is to describe in detail the technical evaluation and progress against benchmarks. The benchmarking strategy was defined in WP1, and this document describes how the benchmarking is implemented for the components in the Minimum Viable Product (MVP) of the MARVEL project. The role of each component in the MVP together with the description of the development status is discussed in detail before the benchmarking process of components is described. This process involves defining the measurement metrics and data, as well as the state-of-the-art baselines, and reporting the measurement results together with the observations about the results. In addition to this, the contribution to MARVEL KPIs per component is described and expected future results are discussed. The final version of this document will be delivered by the end of the project, and it will contain the benchmarking of the full MARVEL framework.
Analysis of Everyday Soundscapes
I worked on the EVERYSOUND project at Tampere University under Tuomas Virtanen, funded by the European Research Council (ERC). The focus was robust methods for sound event detection and acoustic scene classification using machine learning and deep neural networks, with open datasets, standardized evaluation protocols, and listening experiments to keep the research reproducible.
The project's biggest outcome was the DCASE (Detection and Classification of Acoustic Scenes and Events research community, which grew through annual international challenges and workshops into a global benchmark platform for machine listening research — now with hundreds of participants worldwide, and a steady stream of benchmark datasets and high-impact publications.
- Delivered foundational tools, open datasets, and methodologies now widely adopted across academia and industry.
- Established and co-organized the DCASE research community, now a global hub for acoustic scene and event analysis, with its datasets and research outcomes showing up in smart city, surveillance, and assistive technology applications.
- Developed benchmark datasets used by hundreds of researchers worldwide, including the widely adopted TUT/TUNI Acoustic Scenes datasets.
- Published 4 journal articles, 15 conference papers, and 2 book chapters from this work, totaling over 5,000 citations, including the IEEE Signal Processing Society Best Paper Award in 2024.
- Pioneered evaluation metrics and protocols for polyphonic sound event detection and acoustic scene classification, and released the first open-source evaluation toolbox, sed_eval.
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. Acoustic scene classification in dcase 2019 challenge: closed and open set classification and data mismatch setups. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), 164–168. New York University, NY, USA, Oct 2019. 91 cites
Acoustic Scene Classification in DCASE 2019 challenge: closed and open set classification and data mismatch setups
Abstract
Acoustic Scene Classification is a regular task in the DCASE Challenge, with each edition having it as a task. Throughout the years, modifications to the task have included mostly changing the dataset and increasing its size, but recently also more realistic setups have been introduced. In DCASE 2019 Challenge, the Acoustic Scene Classification task includes three subtasks: Subtask A, a closed-set typical supervised classification where all data is recorded with the same device; Subtask B, a closed-set classification setup with mismatched recording devices between training and evaluation data, and Subtask C, an open-set classification setup in which evaluation data could contain acoustic scenes not encountered in the training. In all subtasks, the provided baseline system was significantly outperformed, with top performance being 85.2% for Subtask A, 75.5% for Subtask B, and 67.4% for Subtask C. This paper presents the outcome of DCASE 2019 Challenge Task 1 in terms of submitted systems performance and analysis.
Keywords
Acoustic Scene Classification, DCASE 2019 Challenge, open set classification
Cites: 91 (see at Google Scholar)
Helen L Bear, Toni Heittola, Annamaria Mesaros, Emmanouil Benetos, and Tuomas Virtanen. City classification from multiple real-world sound scenes. In IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 11–15. New Paltz, NY, Oct 2019. 17 cites
City classification from multiple real-world sound scenes
Abstract
The majority of sound scene analysis work focuses on one of two clearly defined tasks: acoustic scene classification or sound event detection. Whilst this separation of tasks is useful for problem definition, they inherently ignore some subtleties of the real-world, in particular how humans vary in how they describe a scene. Some will describe the weather and features within it, others will use a holistic descriptor like `park', and others still will use unique identifiers such as cities or names. In this paper, we undertake the task of automatic city classification to ask whether we can recognize a city from a set of sound scenes? In this problem each city has recordings from multiple scenes. We test a series of methods for this novel task and show that a simple convolutional neural network (CNN) can achieve accuracy of 50%. This is less than the acoustic scene classification task baseline in the DCASE 2018 ASC challenge on the same data. A simple adaptation to the class labels of pairing city labels with grouped scenes, accuracy increases to 52%, closer to the simpler scene classification task. Finally we also formulate the problem in a multi-task learning framework and achieve an accuracy of 56%, outperforming the aforementioned approaches.
Keywords
Acoustic scene classification, location identification, city classification, computational sound scene analysis.
Cites: 17 (see at Google Scholar)
Annamaria Mesaros, Sharath Adavanne, Archontis Politis, Toni Heittola, and Tuomas Virtanen. Joint measurement of localization and detection of sound events. In IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 328–332. New Paltz, NY, Oct 2019. 96 cites
Joint Measurement of Localization and Detection of Sound Events
Abstract
Sound event detection and sound localization or tracking have historically been two separate areas of research. Recent development of sound event detection methods approach also the localization side, but lack a consistent way of measuring the joint performance of the system; instead, they measure the separate abilities for detection and for localization. This paper proposes augmentation of the localization metrics with a condition related to the detection, and conversely, use of location information in calculating the true positives for detection. An extensive evaluation example is provided to illustrate the behavior of such joint metrics. The comparison to the detection only and localization only performance shows that the proposed joint metrics operate in a consistent and logical manner, and characterize adequately both aspects.
Keywords
Sound event detection and localization, performance evaluation
Cites: 96 (see at Google Scholar)
Annamaria Mesaros, Aleksandr Diment, Benjamin Elizalde, Toni Heittola, Emmanuel Vincent, Bhiksha Raj, and Tuomas Virtanen. Sound event detection in the DCASE 2017 Challenge. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(6):992–1006, June 2019. doi:10.1109/TASLP.2019.2907016. 176 cites
Sound event detection in the DCASE 2017 Challenge
Abstract
Each edition of the challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) contained several tasks involving sound event detection in different setups. DCASE 2017 presented participants with three such tasks, each having specific datasets and detection requirements: Task 2, in which target sound events were very rare in both training and testing data, Task 3 having overlapping events annotated in real-life audio, and Task 4, in which only weakly-labeled data was available for training. In this paper, we present the three tasks, including the datasets and baseline systems, and analyze the challenge entries for each task. We observe the popularity of methods using deep neural networks, and the still widely used mel frequency based representations, with only few approaches standing out as radically different. Analysis of the systems behavior reveals that task-specific optimization has a big role in producing good performance; however, often this optimization closely follows the ranking metric, and its maximization/minimization does not result in universally good performance. We also introduce the calculation of confidence intervals based on a jackknife resampling procedure, to perform statistical analysis of the challenge results. The analysis indicates that while the 95% confidence intervals for many systems overlap, there are significant differences in performance between the top systems and the baseline for all tasks.
Keywords
Sound event detection, weak labels, pattern recognition, jackknife estimates, confidence intervals
Cites: 176 (see at Google Scholar)
Irene Martin-Morato, Annamaria Mesaros, Toni Heittola, Tuomas Virtanen, Maximo Cobos, and Francesc J. Ferri. Sound event envelope estimation in polyphonic mixtures. In 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 935–939. May 2019. doi:10.1109/ICASSP.2019.8682858. 24 cites
Sound event envelope estimation in polyphonic mixtures
Abstract
Sound event detection is the task of identifying automatically the presence and temporal boundaries of sound events within an input audio stream. In the last years, deep learning methods have established themselves as the state-of-the-art approach for the task, using binary indicators during training to denote whether an event is active or inactive. However, such binary activity indicators do not fully describe the events, and estimating the envelope of the sounds could provide more precise modeling of their activity. This paper proposes to estimate the amplitude envelopes of target sound event classes in polyphonic mixtures. For training, we use the amplitude envelopes of the target sounds, calculated from mixture signals and, for comparison, from their isolated counterparts. The model is then used to perform envelope estimation and sound event detection. Results show that the envelope estimation allows good modeling of the sounds activity, with detection results comparable to current state-of-the art.
Keywords
Sound event detection, Envelope estimation, Deep Neural Networks
Cites: 24 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. A multi-device dataset for urban acoustic scene classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), 9–13. November 2018. 544 cites
A multi-device dataset for urban acoustic scene classification
Abstract
This paper introduces the acoustic scene classification task of DCASE 2018 Challenge and the TUT Urban Acoustic Scenes 2018 dataset provided for the task, and evaluates the performance of a baseline system in the task. As in previous years of the challenge, the task is defined for classification of short audio samples into one of predefined acoustic scene classes, using a supervised, closed-set classification setup. The newly recorded TUT Urban Acoustic Scenes 2018 dataset consists of ten different acoustic scenes and was recorded in six large European cities, therefore it has a higher acoustic variability than the previous datasets used for this task, and in addition to high-quality binaural recordings, it also includes data recorded with mobile devices. We also present the baseline system consisting of a convolutional neural network and its performance in the subtasks using the recommended cross-validation setup.
Keywords
Acoustic scene classification, DCASE challenge, public datasets, multi-device data
Cites: 544 (see at Google Scholar)
Guangpu Huang, Toni Heittola, and Tuomas Virtanen. Using sequential information in polyphonic sound event detection. In 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), 291–295. September 2018. doi:10.1109/IWAENC.2018.8521367. 10 cites
Using Sequential Information in Polyphonic Sound Event Detection
Abstract
To detect the class, and start and end times of sound events in real world recordings is a challenging task. Current computer systems often show relatively high frame-wise accuracy but low event-wise accuracy. In this paper, we attempted to merge the gap by explicitly including sequential information to improve the performance of a state-of-the-art polyphonic sound event detection system. We propose to 1) use delayed predictions of event activities as additional input features that are fed back to the neural network; 2) build N-grams to model the co-occurrence probabilities of different events; 3) use sequential loss to train neural networks. Our experiments on a corpus of real world recordings show that the N-grams could smooth the spiky output of a state-of-the-art neural network system, and improve both the frame-wise and the event-wise metrics.
Keywords
Polyphonic sound event detection;language modelling;sequential information
Cites: 10 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. Acoustic scene classification: an overview of DCASE 2017 challenge entries. In 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), 411–415. September 2018. doi:10.1109/IWAENC.2018.8521242. 107 cites
Acoustic Scene Classification: An Overview of DCASE 2017 Challenge Entries
Abstract
We present an overview of the challenge entries for the Acoustic Scene Classification task of DCASE 2017 Challenge. Being the most popular task of the challenge, acoustic scene classification entries provide a wide variety of approaches for comparison, with a wide performance gap from top to bottom. Analysis of the submissions confirms once more the popularity of deep-learning approaches and mel-frequency representations. Statistical analysis indicates that the top ranked system performed significantly better than the others, and that combinations of top systems are capable of reaching close to perfect performance on the given data.
Keywords
acoustic scene classification, audio classification, DCASE challenge
Cites: 107 (see at Google Scholar)
A. Mesaros, T. Heittola, E. Benetos, P. Foster, M. Lagrange, T. Virtanen, and M. D. Plumbley. Detection and classification of acoustic scenes and events: outcome of the dcase 2016 challenge. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(2):379–393, Feb 2018. doi:10.1109/TASLP.2017.2778423. 406 cites
Detection and Classification of Acoustic Scenes and Events: Outcome of the DCASE 2016 Challenge
Abstract
Public evaluation campaigns and datasets promote active development in target research areas, allowing direct comparison of algorithms. The second edition of the challenge on detection and classification of acoustic scenes and events (DCASE 2016) has offered such an opportunity for development of the state-of-the-art methods, and succeeded in drawing together a large number of participants from academic and industrial backgrounds. In this paper, we report on the tasks and outcomes of the DCASE 2016 challenge. The challenge comprised four tasks: acoustic scene classification, sound event detection in synthetic audio, sound event detection in real-life audio, and domestic audio tagging. We present each task in detail and analyze the submitted systems in terms of design and performance. We observe the emergence of deep learning as the most popular classification method, replacing the traditional approaches based on Gaussian mixture models and support vector machines. By contrast, feature representations have not changed substantially throughout the years, as mel frequency-based representations predominate in all tasks. The datasets created for and used in DCASE 2016 are publicly available and are a valuable resource for further research.
Keywords
Acoustics;Event detection;Hidden Markov models;Speech;Speech processing;Tagging;Acoustic scene classification;audio datasets;pattern recognition;sound event detection
Cites: 406 (see at Google Scholar)
Toni Heittola, Emre Çakır, and Tuomas Virtanen. The Machine Learning Approach for Analysis of Sound Scenes and Events, pages 13–40. Springer International Publishing, Cham, 2018. 50 cites
The Machine Learning Approach for Analysis of Sound Scenes and Events
Abstract
This chapter explains the basic concepts in computational methods used for analysis of sound scenes and events. Even though the analysis tasks in many applications seem different, the underlying computational methods are typically based on the same principles. We explain the commonalities between analysis tasks such as sound event detection, sound scene classification, or audio tagging. We focus on the machine learning approach, where the sound categories (i.e., classes) to be analyzed are defined in advance. We explain the typical components of an analysis system, including signal pre-processing, feature extraction, and pattern classification. We also preset an example system based on multi-label deep neural networks, which has been found to be applicable in many analysis tasks discussed in this book. Finally, we explain the whole processing chain that involves developing computational audio analysis systems.
Cites: 50 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Dan Ellis. Datasets and Evaluation, pages 147–179. Springer International Publishing, Cham, 2018. 35 cites
Datasets and Evaluation
Abstract
Developing computational systems requires methods for evaluating their performance to guide development and compare alternate approaches. A reliable evaluation procedure for a classification or recognition system will involve a standard dataset of example input data along with the intended target output, and well-defined metrics to compare the systems' outputs with this ground truth. This chapter examines the important factors in the design and construction of evaluation datasets and goes through the metrics commonly used in system evaluation, comparing their properties. We include a survey of currently available datasets for environmental sound scene and event recognition and conclude with advice for designing evaluation protocols.
Cites: 35 (see at Google Scholar)
Tuomas Virtanen, Annamaria Mesaros, Toni Heittola, Aleksandr Diment, Emmanuel Vincent, Emmanouil Benetos, and Benjamin Martinez Elizalde. Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE2017). Tampere University of Technology. Laboratory of Signal Processing, 2017. ISBN 978-952-15-4042-4. ISBN (Electronic): 978-952-15-4042-4. 10 cites
Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE2017)
Cites: 10 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, Aleksandr Diment, Benjamin Elizalde, Ankit Shah, Emmanuel Vincent, Bhiksha Raj, and Tuomas Virtanen. DCASE 2017 challenge setup: tasks, datasets and baseline system. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE2017), 85–92. November 2017. 630 cites
DCASE 2017 Challenge Setup: Tasks, Datasets and Baseline System
Abstract
DCASE 2017 Challenge consists of four tasks: acoustic scene classification, detection of rare sound events, sound event detection in real-life audio, and large-scale weakly supervised sound event detection for smart cars. This paper presents the setup of these tasks: task definition, dataset, experimental setup, and baseline system results on the development dataset. The baseline systems for all tasks rely on the same implementation using multilayer perceptron and log mel-energies, but differ in the structure of the output layer and the decision making process, as well as the evaluation of system output using task specific metrics.
Keywords
Sound scene analysis, Acoustic scene classification, Sound event detection, Audio tagging, Rare sound events
Cites: 630 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. Assessment of human and machine performance in acoustic scene classification: DCASE 2016 case study. In 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 319–323. IEEE Computer Society, 2017. doi:10.1109/WASPAA.2017.8170047. 32 cites
Assessment of Human and Machine Performance in Acoustic Scene Classification: DCASE 2016 Case Study
Abstract
Human and machine performance in acoustic scene classification is examined through a parallel experiment using TUT Acoustic Scenes 2016 dataset. The machine learning perspective is presented based on the systems submitted for the 2016 challenge on Detection and Classification of Acoustic Scenes and Events. The human performance, assessed through a listening experiment, was found to be significantly lower than machine performance. Test subjects exhibited different behavior throughout the experiment, leading to significant differences in performance between groups of subjects. An expert listener trained for the task obtained similar accuracy to the average of submitted systems, comparable also to previous studies of human abilities in recognizing everyday acoustic scenes.
Cites: 32 (see at Google Scholar)
Emre Cakir, Giambattista Parascandolo, Toni Heittola, Heikki Huttunen, and Tuomas Virtanen. Convolutional recurrent neural networks for polyphonic sound event detection. Transactions on Audio, Speech and Language Processing: Special issue on Sound Scene and Event Analysis, 25(6):1291–1303, June 2017. doi:10.1109/TASLP.2017.2690575. 838 cites
Convolutional Recurrent Neural Networks for Polyphonic Sound Event Detection
Abstract
Sound events often occur in unstructured environments where they exhibit wide variations in their frequency content and temporal structure. Convolutional neural networks (CNN) are able to extract higher level features that are invariant to local spectral and temporal variations. Recurrent neural networks (RNNs) are powerful in learning the longer term temporal context in the audio signals. CNNs and RNNs as classifiers have recently shown improved performances over established methods in various sound recognition tasks. We combine these two approaches in a Convolutional Recurrent Neural Network (CRNN) and apply it on a polyphonic sound event detection task. We compare the performance of the proposed CRNN method with CNN, RNN, and other established methods, and observe a considerable improvement for four different datasets consisting of everyday sound events.
Cites: 838 (see at Google Scholar)
Tuomas Virtanen, Annamaria Mesaros, Toni Heittola, Mark D. Plumbley, Peter Foster, Emmanouil Benetos, and Mathieu Lagrange. Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016 Workshop (DCASE2016). Tampere University of Technology. Department of Signal Processing, 2016. ISBN 978-952-15-3807-0. ISBN (Electronic): 978-952-15-3807-0. 10 cites
Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016 Workshop (DCASE2016)
Cites: 10 (see at Google Scholar)
Emre Cakir, Toni Heittola, and Tuomas Virtanen. Domestic audio tagging with convolutional neural networks. Technical Report, DCASE2016 Challenge, September 2016. 31 cites
Domestic Audio Tagging with Convolutional Neural Networks
Abstract
In this paper, the method used in our submission for DCASE2016 challenge task 4 (domestic audio tagging) is described. The use of convolutional neural networks (CNN) to label the audio signals recorded in a domestic (home) environment is investigated. A relative 23.8% improvement over the Gaussian mixture model (GMM) baseline method is observed over the development dataset for the challenge.
Cites: 31 (see at Google Scholar)
Sharath Adavanne, Giambattista Parascandolo, Pasi Pertila, Toni Heittola, and Tuomas Virtanen. Sound event detection in multichannel audio using spatial and harmonic features. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2016 Workshop (DCASE2016), 6–10. September 2016. 150 cites
Sound Event Detection in Multichannel Audio Using Spatial and Harmonic Features
Abstract
In this paper, we propose the use of spatial and harmonic features in combination with long short term memory (LSTM) recurrent neural network (RNN) for automatic sound event detection (SED) task. Real life sound recordings typically have many overlapping sound events, making it hard to recognize with just mono channel audio. Human listeners have been successfully recognizing the mixture of overlapping sound events using pitch cues and exploiting the stereo (multichannel) audio signal available at their ears to spatially localize these events. Traditionally SED systems have only been using mono channel audio, motivated by the human listener we propose to extend them to use multichannel audio. The proposed SED system is compared against the state of the art mono channel method on the development subset of TUT sound events detection 2016 database. The proposed method improves the F-score by 3.75% while reducing the error rate by 6%
Keywords
Sound event detection, multichannel, time difference of arrival, pitch, recurrent neural networks, long short term memory
Cites: 150 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. TUT database for acoustic scene classification and sound event detection. In 24th European Signal Processing Conference 2016 (EUSIPCO 2016), 1128–1132. Budapest, Hungary, Aug 2016. doi:10.1109/EUSIPCO.2016.7760424. 821 cites
TUT Database for Acoustic Scene Classification and Sound Event Detection
Abstract
We introduce TUT Acoustic Scenes 2016 database for environmental sound research, consisting ofbinaural recordings from 15 different acoustic environments. A subset of this database, called TUT Sound Events 2016, contains annotations for individual sound events, specifically created for sound event detection. TUT Sound Events 2016 consists of residential area and home environments, and is manually annotated to mark onset, offset and label of sound events. In this paper we present the recording and annotation procedure, the database content, a recommended cross-validation setup and performance of supervised acoustic scene classification system and event detection baseline system using mel frequency cepstral coefficients and Gaussian mixture models. The database is publicly released to provide support for algorithm development and common ground for comparison of different techniques.
Keywords
audio recording;audio signal processing;Gaussian mixture models;TUT database;acoustic scene classification;binaural recordings;environmental sound research;mel frequency cepstral coefficients;sound event detection;Automobiles;Databases;Europe;Event detection;Mel frequency cepstral coefficient;Signal processing
Cites: 821 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Tuomas Virtanen. Metrics for polyphonic sound event detection. Applied Sciences, 6(6):162, 2016. URL: http://www.mdpi.com/2076-3417/6/6/162, doi:10.3390/app6060162. 796 cites
Metrics for Polyphonic Sound Event Detection
Abstract
This paper presents and discusses various metrics proposed for evaluation of polyphonic sound event detection systems used in realistic situations where there are typically multiple sound sources active simultaneously. The system output in this case contains overlapping events, marked as multiple sounds detected as being active at the same time. The polyphonic system output requires a suitable procedure for evaluation against a reference. Metrics from neighboring fields such as speech recognition and speaker diarization can be used, but they need to be partially redefined to deal with the overlapping events. We present a review of the most common metrics in the field and the way they are adapted and interpreted in the polyphonic case. We discuss segment-based and event-based definitions of each metric and explain the consequences of instance-based and class-based averaging using a case study. In parallel, we provide a toolbox containing implementations of presented metrics.
Cites: 796 (see at Google Scholar)
Aleksandr Diment, Emre Cakir, Toni Heittola, and Tuomas Virtanen. Automatic recognition of environmental sound events using all-pole group delay features. In 23rd European Signal Processing Conference 2015 (EUSIPCO 2015). Nice, France, 2015. 17 cites
Automatic recognition of environmental sound events using all-pole group delay features
Abstract
A feature based on the group delay function from all-pole models (APGD) is proposed for environmental sound event recognition. The commonly used spectral features take into account merely the magnitude information, whereas the phase is overlooked due to the complications related to its interpretation. Additional information concealed in the phase is hypothesised to be beneficial for sound event recognition. The APGD is an approach to inferring phase information, which has shown applicability for analysis of speech and music signals and is now studied in environmental audio. The evaluation is performed within a multi-label deep neural network (DNN) framework on a diverse real-life dataset of environmental sounds. It shows performance improvement compared to the baseline log mel-band energy case. In combination with the magnitude-based features, APGD demonstrates further improvement.
Cites: 17 (see at Google Scholar)
Emre Cakir, Toni Heittola, Heikki Huttunen, and Tuomas Virtanen. Multi-label vs. combined single-label sound event detection with deep neural networks. In 23rd European Signal Processing Conference 2015 (EUSIPCO 2015). Nice, France, 2015. 67 cites
Multi-Label vs. Combined Single-Label Sound Event Detection With Deep Neural Networks
Abstract
In real-life audio scenes, many sound events from different sources are simultaneously active, which makes the automatic sound event detection challenging. In this paper, we compare two different deep learning methods for the detection of environmental sound events: combined single-label classification and multi-label classification. We investigate the accuracy of both methods on the audio with different levels of polyphony. Multi-label classification achieves an overall 62.8% accuracy, whereas combined single-label classification achieves a very close 61.9% accuracy. The latter approach offers more flexibility on real-world applications by gathering the relevant group of sound events in a single classifier with various combinations.
Cites: 67 (see at Google Scholar)
Emre Cakir, Toni Heittola, Heikki Huttunen, and Tuomas Virtanen. Polyphonic sound event detection using multi label deep neural networks. In The International Joint Conference on Neural Networks 2015 (IJCNN 2015). Cill Airne, Eire, 2015. 407 cites
Polyphonic Sound Event Detection Using Multi Label Deep Neural Networks
Abstract
In this paper, the use of multi label neural networks are proposed for detection of temporally overlapping sound events in realistic environments. Real-life sound recordings typically have many overlapping sound events, making it hard to recognize each event with the standard sound event detection methods. Frame-wise spectral-domain features are used as inputs to train a deep neural network for multi label classification in this work. The model is evaluated with recordings from realistic everyday environments and the obtained overall accuracy is 58.9%. The method is compared against a state-of-the-art method using non-negative matrix factorization as a pre-processing stage and hidden Markov models as a classifier. The proposed method improves the accuracy by 19% percentage points overall.
Cites: 407 (see at Google Scholar)
Real-Time Sound Event Detection for Assistive Technology Applications
The SmartHear project, funded by Tekes' TUTL (Business from Research Ideas) program, aimed to turn audio technology into assistive technology for people with hearing impairments — exploring real-time sound detection in the home, as a joint effort between Tampere University of Technology, Tampere University, and Aalto University.
The system detected and classified critical sounds like doorbells, alarms, and speech from a microphone array in a controlled indoor setting, aiming for the accuracy a responsive assistive application would need.
We built a functional prototype on edge computing hardware with custom-trained neural networks for environmental sound classification, and evaluated it through technical tests and user trials. Feedback from users with hearing impairments shaped the interface and alert design, and fed into exploring commercialization paths — including integration with smart home ecosystems and assistive hearing technologies.
Laying the Groundwork for Sound Event Detection in Natural Environments
For several years, our research group explored the frontiers of computational auditory scene analysis through an industrial research collaboration with Nokia, funded by Tekes. What began as curiosity about how machines could understand everyday sounds evolved into work that helped shape the early foundations of real-world sound event detection.
We were among the first to tackle sound event detection in uncontrolled real-life environments — far from the clean, idealized conditions of lab recordings. That led to new methods for context-aware detection, source separation, and overlapping sound event modeling, widely cited and influential in the field's early days. Along the way we also explored summarizing and synthesizing environmental audio, creating location-specific audio textures that captured a place's acoustic signature.
A key part of this project was leading the creation of several environmental audio datasets — planning the data collection and annotation with a strong emphasis on quality. These datasets later became a cornerstone for many of our state-of-the-art studies, well beyond the project's original scope. We also studied how people perceive soundscapes, how they tell apart similar urban ambiances, and what makes an environment feel familiar or distinct — human-centered work that grounded the technical side in real-world experience.
- The collaboration produced a series of publications and patents, helped establish our research group's standing in the field, and laid groundwork for years of follow-on research.
- Pioneering real-world sound event detection: The collaboration was among the first to develop and validate methods for detecting overlapping sound events in uncontrolled, real-world environments. These efforts culminated in highly cited publications (over 1100 citations).
- Context-aware and overlapping event modeling: Through innovations in source separation and context-dependent modeling, we addressed the challenges of overlapping sound events and significantly improved detection accuracy in complex acoustic scenes.
- Audio summarization and synthesis: The research explored novel techniques for audio summarization and location-specific audio texture synthesis, enabling efficient representation and playback of environmental soundscapes.
- Audio data management and dataset creation: design and construction of environmental audio datasets, including the planning and execution of data collection and annotation processes.
Method for creating location-specific audio textures
Abstract
An approach is proposed for creating location-specific audio textures for virtual location-exploration services. The presented approach creates audio textures by processing a small amount of audio recorded at a given location, providing a cost-effective way to produce a versatile audio signal that characterizes the location. The resulting texture is non-repetitive and conserves the location-specific characteristics of the audio scene, without the need of collecting large amount of audio from each location. The method consists of two stages: analysis and synthesis. In the analysis stage, the source audio recording is segmented into homogeneous segments. In the synthesis stage, the audio texture is created by randomly drawing segments from the source audio so that the consecutive segments will have timbral similarity near the segment boundaries. Results obtained in listening experiments show that there is no statistically significant difference in the audio quality or location-specificity of audio when the created audio textures are compared to excerpts of the original recordings. Therefore, the proposed audio textures could be utilized in virtual location-exploration services. Examples of source signals and audio textures created from them are available at www.cs.tut.fi/~heittolt/audiotexture.
Cites: 12 (see at Google Scholar)
Toni Heittola, Annamaria Mesaros, Tuomas Virtanen, and Moncef Gabbouj. Supervised model training for overlapping sound events based on unsupervised source separation. In Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on, 8677–8681. Vancouver, Canada, 2013. IEEE Computer Society. URL: http://dx.doi.org/10.1109/ICASSP.2013.6639360, doi:10.1109/ICASSP.2013.6639360. 97 cites
Supervised Model Training for Overlapping Sound Events Based on Unsupervised Source Separation
Abstract
Sound event detection is addressed in the presence of overlapping sounds. Unsupervised sound source separation into streams is used as a preprocessing step to minimize the interference of overlapping events. This poses a problem in supervised model training, since there is no knowledge about which separated stream contains the targeted sound source. We propose two iterative approaches based on EM algorithm to select the most likely stream to contain the target sound: one by selecting always the most likely stream and another one by gradually eliminating the most unlikely streams from the training. The approaches were evaluated with a database containing recordings from various contexts, against the baseline system trained without applying stream selection. Both proposed approaches were found to give a reasonable increase of 8 percentage units in the detection accuracy.
Keywords
acoustic event detection;acoustic pattern recognition;sound source separation;supervised model training
Cites: 97 (see at Google Scholar)
Toni Heittola, Annamaria Mesaros, Antti Eronen, and Tuomas Virtanen. Context-dependent sound event detection. EURASIP Journal on Audio, Speech and Music Processing, 2013. 309 cites
Context-Dependent Sound Event Detection
Abstract
The work presented in this article studies how the context information can be used in the automatic sound event detection process, and how the detection system can benefit from such information. Humans are using context information to make more accurate predictions about the sound events and ruling out unlikely events given the context. We propose a similar utilization of context information in the automatic sound event detection process. The proposed approach is composed of two stages: automatic context recognition stage and sound event detection stage. Contexts are modeled using Gaussian mixture models and sound events are modeled using three-state left-to-right hidden Markov models. In the first stage, audio context of the tested signal is recognized. Based on the recognized context, a context-specific set of sound event classes is selected for the sound event detection stage. The event detection stage also uses context-dependent acoustic models and count-based event priors. Two alternative event detection approaches are studied. In the first one, a monophonic event sequence is outputted by detecting the most prominent sound event at each time instance using Viterbi decoding. The second approach introduces a new method for producing polyphonic event sequence by detecting multiple overlapping sound events using multiple restricted Viterbi passes. A new metric is introduced to evaluate the sound event detection performance with various level of polyphony. This combines the detection accuracy and coarse time-resolution error into one metric, making the comparison of the performance of detection algorithms simpler. The two-step approach was found to improve the results substantially compared to the context-independent baseline system. In the block-level, the detection accuracy can be almost doubled by using the proposed context-dependent event detection.
Cites: 309 (see at Google Scholar)
Dani Korpi, Toni Heittola, Timo Partala, Antti Eronen, Annamaria Mesaros, and Tuomas Virtanen. On the human ability to discriminate audio ambiances from similar locations of an urban environment. Personal and Ubiquitous Computing, 17(4):761–769, 2013. URL: http://dx.doi.org/10.1007/s00779-012-0625-z, doi:10.1007/s00779-012-0625-z. 2 cites
On the human ability to discriminate audio ambiances from similar locations of an urban environment
Abstract
When developing advanced location-based systems augmented with audio ambiances, it would be cost-effective to use a few representative samples from typical environments for describing a larger number of similar locations. The aim of this experiment was to study the human ability to discriminate audio ambiances recorded in similar locations of the same urban environment. A listening experiment consisting of material from three different environments and nine different locations was carried out with nineteen subjects to study the credibility of audio representations for certain environments which would diminish the need for collecting huge audio databases. The first goal was to study to what degree humans are able to recognize whether the recording has been made in an indicated location or in another similar location, when presented with the name of the place, location on a map, and the associated audio ambiance. The second goal was to study whether the ability to discriminate audio ambiances from different locations is affected by a visual cue, by presenting additional information in form of a photograph of the suggested location. The results indicate that audio ambiances from similar urban areas of the same city differ enough so that it is not acceptable to use a single recording as ambience to represent different yet similar locations. Including an image was found to increase the perceived credibility of all the audio samples in representing a certain location. The results suggest that developers of audio-augmented location-based systems should aim at using audio samples recorded on-site for each location in order to achieve a credible impression.
Keywords
Listening experiment; Location recognition; Audio-visual perception; Audio ambiance
Cites: 2 (see at Google Scholar)
Antti Eronen, Toni Heittola, Annamaria Mesaros, and Tuomas Virtanen. Method and apparatus for providing media event suggestions. 09 2012. URL: http://www.google.com/patents/US20130232412.
Method and apparatus for providing media event suggestions
Abstract
Various methods are described for providing media event suggestions based at least in part on a co-occurrence model. One example method may comprise receiving a selection of at least one media event to include in a media composition. Additionally, the method may comprise determining at least one suggested media event based at least in part on the at least one media events. The method may further comprise causing display of the at least one suggested media event. Similar and related methods, apparatuses, and computer program products are also provided.
Antti Eronen, Miska Hannuksela, Toni Heittola, Annamaria Mesaros, and Tuomas Virtanen. Method and apparatus for generating an audio summary of a location. 09 2012. URL: http://www.google.com/patents/WO2013128064A1. 12 cites
Method and apparatus for generating an audio summary of a location
Abstract
Various methods are described for generating an audio summary representing a location on a place exploration service. One example method may comprise receiving at least one audio file. The method may further comprise dividing the at least one audio file into one or more audio segments. Additionally, the method may comprise determining a representative audio segment for each of the one or more audio segments. The method may further comprise generating an audio summary of the at least one audio file by combining one or more of the representative audio segments of the one or more audio segments. Similar and related methods, apparatuses, and computer program products are also provided.
Cites: 12 (see at Google Scholar)
Sound Event Detection in Multisource Environments Using Source Separation
Abstract
This paper proposes a sound event detection system for natural multisource environments, using a sound source separation front-end. The recognizer aims at detecting sound events from various everyday contexts. The audio is preprocessed using non-negative matrix factorization and separated into four individual signals. Each sound event class is represented by a Hidden Markov Model trained using mel frequency cepstral coefficients extracted from the audio. Each separated signal is used individually for feature extraction and then segmentation and classification of sound events using the Viterbi algorithm. The separation allows detection of a maximum of four overlapping events. The proposed system shows a significant increase in event detection accuracy compared to a system able to output a single sequence of events.
Cites: 168 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, and Anssi Klapuri. Latent semantic analysis in sound event detection. In 19th European Signal Processing Conference (EUSIPCO 2011), 1307–1311. 2011. 68 cites
Latent Semantic Analysis in Sound Event Detection
Abstract
This paper presents the use of probabilistic latent semantic analysis (PLSA) for modeling co-occurrence of overlapping sound events in audio recordings from everyday audio environments such as office, street or shop. Co-occurrence of events is represented as the degree of their overlapping in a fixed length segment of polyphonic audio. In the training stage, PLSA is used to learn the relationships between individual events. In detection, the PLSA model continuously adjusts the probabilities of events according to the history of events detected so far. The event probabilities provided by the model are integrated into a sound event detection system that outputs a monophonic sequence of events. The model offers a very good representation of the data, having low perplexity on test recordings. Using PLSA for estimating prior probabilities of events provides an increase of event detection accuracy to 35%, compared to 30% for using uniform priors for the events. There are different levels of performance increase in different audio contexts, with few contexts showing significant improvement.
Keywords
sound event detection, latent semantic analysis
Cites: 68 (see at Google Scholar)
Toni Heittola, Annamaria Mesaros, Tuomas Virtanen, and Antti Eronen. Sound event detection and context recognition. In Proceedings of Akustiikkapäivät 2011, 51–56. Tampere, Finland, 2011. 3 cites
Sound Event Detection and Context Recognition
Keywords
sound event detection, context recognition
Cites: 3 (see at Google Scholar)
Toni Heittola, Annamaria Mesaros, Antti Eronen, and Tuomas Virtanen. Audio context recognition using audio event histograms. In 18th European Signal Processing Conference (EUSIPCO 2010), 1272–1276. Aalborg, Denmark, 2010. 113 cites
Audio Context Recognition Using Audio Event Histograms
Abstract
This paper presents a method for audio context recognition, meaning classification between everyday environments. The method is based on representing each audio context using a histogram of audio events which are detected using a supervised classifier. In the training stage, each context is modeled with a histogram estimated from annotated training data. In the testing stage, individual sound events are detected in the unknown recording and a histogram of the sound event occurrences is built. Context recognition is performed by computing the cosine distance between this histogram and event histograms of each context from the training database. Term frequency--inverse document frequency weighting is studied for controlling the importance of different events in the histogram distance calculation. An average classification accuracy of 89% is obtained in the recognition between ten everyday contexts. Combining the event based context recognition system with more conventional audio based recognition increases the recognition rate to 92%.
Cites: 113 (see at Google Scholar)
Annamaria Mesaros, Toni Heittola, Antti Eronen, and Tuomas Virtanen. Acoustic event detection in real-life recordings. In 18th European Signal Processing Conference (EUSIPCO 2010), 1267–1271. Aalborg, Denmark, 2010. 422 cites
Acoustic Event Detection in Real-life Recordings
Abstract
This paper presents a system for acoustic event detection in recordings from real life environments. The events are modeled using a network of hidden Markov models; their size and topology is chosen based on a study of isolated events recognition. We also studied the effect of ambient background noise on event classification performance. On real life recordings, we tested recognition of isolated sound events and event detection. For event detection, the system performs recognition and temporal positioning of a sequence of events. An accuracy of 24% was obtained in classifying isolated sound events into 61 classes. This corresponds to the accuracy of classifying between 61 events when mixed with ambient background noise at 0dB signal-to-noise ratio. In event detection, the system is capable of recognizing almost one third of the events, and the temporal positioning of the events is not correct for 84% of the time.
Cites: 422 (see at Google Scholar)
Acoustic Monitoring
Acoustic monitoring is the process of using sound sensors and signal processing technologies to detect, analyze, and interpret environmental sounds. It enables real-time awareness of events or changes in a space without the need for visual surveillance.
Healthcare Environments
As the elderly population grows and care costs rise, acoustic monitoring offers a way to keep tabs on wellbeing without cameras. Over four years I worked on both pre-commercialization and commercialization of audio analytics for healthcare monitoring.
In the pre-commercialization phase (under Tuomas Virtanen, EVERYSOUND, ERC), we built sound event detection systems for healthcare environments — collecting and annotating real-world data, then optimizing algorithms for accuracy and robustness. The system was piloted in a nursing home with a service provider partner.
The follow-on SmartSound project, funded by Business Finland's TUTL program, pushed the technology toward commercialization: a real-time, edge-compatible prototype, piloted again in nursing homes, plus market research that shaped our value proposition — with a privacy focus strong enough that we filed an international patent on privacy-preserving sound representation.
- Developed, piloted, and demonstrated the practical viability of an AI-based sound event detection system tailored for healthcare environments.
- Successfully conducted real-world deployments in nursing homes during both pre-commercialization and commercialization phases.
- Built a real-time, edge-compatible prototype with privacy-preserving features.
- International patent for the privacy-focused technology.
- Designed and implemented a complete system architecture, including acoustic sensors, backend infrastructure, and user interface.
Tuomas Virtanen, Toni Heittola, Shuyang Zhao, Shayan Gharib, and Konstantinos Drosos. Privacy-preserving sound representation. 10 2023. Pending, US Patent App. 18/025,240. URL: https://patents.google.com/patent/US20230317086A1/en. 1 cite
Privacy-preserving sound representation
Abstract
According to an example embodiment, a method (200) for audio-based monitoring is provided, the method (200) comprising: deriving (202), via usage of a predefined conversion model (M), based on audio data that represents sounds captured in a monitored space, one or more audio features that are descriptive of at least one characteristic of said sounds; identifying (204) respective occurrences of one or more predefined acoustic events in said space based on the one or more audio features; and carrying out (206), in response to identifying an occurrence of at least one of said one or more predefined acoustic events, one or more predefined actions associated with said at least one of said one or more predefined acoustic events, wherein said conversion model (M) is trained to provide said one or more audio features such that they include information that facilitates identification of respective occurrences of said one or more predefined acoustic events while preventing identification of speech characteristics.
Cites: 1 (see at Google Scholar)
Intelligent Noise Monitoring
Environmental noise is a growing concern for public health, urban planning, and quality of life — but traditional monitoring, based on manual sound level measurements, misses the complexity of real urban acoustic environments. Two projects I worked on tackled this by adding automatic sound source classification to sensor networks, so they could tell traffic, construction, and human activity apart and give more context-aware noise readings.
The first, on acoustic intelligence and surveillance systems, was funded through Tekes' TUTL program with Tampere University of Technology, VTT Technical Research Centre of Finland, and the University of Eastern Finland. We identified application areas and commercialization paths, and built a system of independent acoustic sensors feeding a backend server that automatically identifies sound sources, with a web interface for the public, authorities, and site administrators — demonstrated successfully at prototype stage.
The second project, with Tampere University of Technology and VTT, took the concept into the field: pilots at an industrial site, a leisure harbor, and an outdoor shooting range in Finland, run in cooperation with the officials responsible for managing noise at each site. Their feedback throughout the pilot shaped the system's features.
- Development of robust sound classification algorithms tailored for urban noise monitoring
- Implementation of an active learning pipeline that significantly reduced manual annotation effort across over 1000 hours of audio data
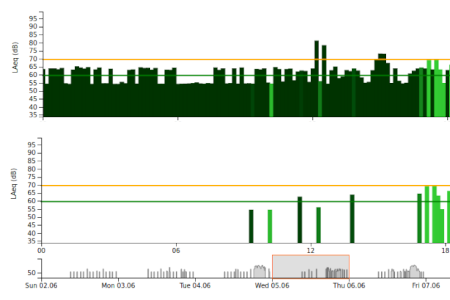
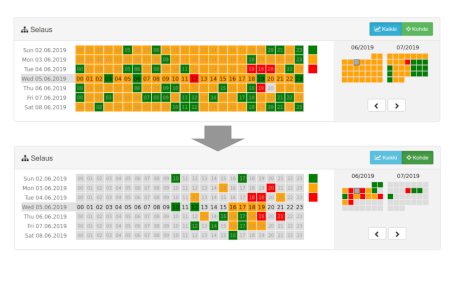
- Creation of a web-based user interface for real-time visualization of noise levels and sound sources
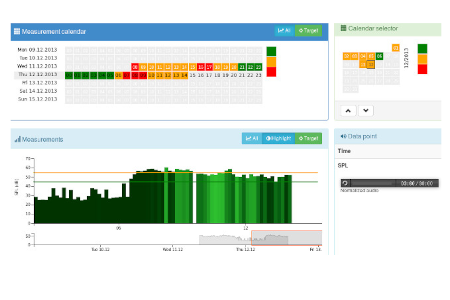
Portal view
Calendar view
SPLs for the target sound source
Panu Maijala, Toni Heittola, and Tuomas Virtanen. Ympäristömelun mittaaminen käyttäen automaattista lähteiden tunnistusta. In Akustiikkapäivät 2019, 196–206. Oulu, Nov 2019.
Ympäristömelun mittaaminen käyttäen automaattista lähteiden tunnistusta
Abstract
Jatkuvatoimisen ympäristömelun mittaamisen suuri haaste on ollut eri äänilähteiden osuuksien erottelu mittauksen aikana vallinneesta kokonaisäänitasosta. Yleensä mittaus suoritetaan selkeästi osoitettavissa olevan melulähteen vuoksi ja lopputuloksesta pyritään poistamaan muiden melulähteiden vaikutus. Ajallisesti lyhyessä mittaustapahtumassa mittaaja voi todentaa tilanteen joko kuuntelemalla mittaushetkellä tai tallennetusta äänestä jälkikäteen. Olemme toteuttaneet hahmontunnistukseen perustuvan luokittelualgoritmin äänitasomittariin ja testanneet sitä useissa eri kohteissa. Tässä paperissa kerromme uudesta äänitasomittarikonseptista, siihen toteutetusta opetetusta luokittelijasta ja luokittelijan suorituskyvystä pilottitutkimuksemme aikana. Lisäksi kerromme kohtaamistamme haasteista ja ratkaisuista niihin.
Panu Maijala, Zhao Shuyang, Toni Heittola, and Tuomas Virtanen. Environmental noise monitoring using source classification in sensors. Applied Acoustics, 129(6):258–267, January 2018. doi:10.1016/j.apacoust.2017.08.006. 147 cites
Environmental noise monitoring using source classification in sensors
Abstract
Environmental noise monitoring systems continuously measure sound levels without assigning these measurements to different noise sources in the acoustic scenes, therefore incapable of identifying the main noise source. In this paper a feasibility study is presented on a new monitoring concept in which an acoustic pattern classification algorithm running in a wireless sensor is used to automatically assign the measured sound level to different noise sources. A supervised noise source classifier is learned from a small amount of manually annotated recordings and the learned classifier is used to automatically detect the activity of target noise source in the presence of interfering noise sources. The sensor is based on an inexpensive credit-card-sized single-board computer with a microphone and associated electronics and wireless connectivity. The measurement results and the noise source information are transferred from the sensors scattered around the measurement site to a cloud service and a noise portal is used to visualise the measurements to users. The proposed noise monitoring concept was piloted on a rock crushing site. The system ran reliably over 50 days on site, during which it was able to recognise more than 90% of the noise sources correctly. The pilot study shows that the proposed noise monitoring system can reduce the amount of required human validation of the sound level measurements when the target noise source is clearly defined.
Keywords
Environmental noise monitoring, Acoustic pattern classification, Wireless sensor network, Cloud service
Cites: 147 (see at Google Scholar)
Music Information Retrieval
Understanding the timbre of musical instruments or drums are an important issue for automatic music transcription, music information retrieval and computational auditory scene analysis. In particular, recent worldwide popularization of online music distribution services and portable digital music players makes musical instrument recognition even more important.
Musical Instrument Recognition
Recognizing musical instruments in polyphonic audio is hard mainly because of overlapping spectral content between simultaneous sources. My research tackled the realistic case of multi-instrumental polyphonic audio, where interference between concurrent sounds limits recognition accuracy — by first separating the mixture into individual sound sources to reduce that interference before classification.
This work, part of a doctoral study at the Tampere Graduate School in Information Science and Engineering, used source-filter models for sound separation to isolate instrument-specific characteristics from polyphonic mixtures. It won the Best Paper Award at ISMIR 2009 for "Musical Instrument Recognition in Polyphonic Audio Using Source-Filter Model for Sound Separation."
- Integrated source-filter modeling techniques into the recognition pipeline, improving separation of overlapping instrument sounds and classification performance.
- Award-winning research (Best Paper Award at ISMIR 2009), with lasting influence on musical instrument recognition research in the pre-deep learning era.
Aleksandr Diment, Rajan Padmanabhan, Toni Heittola, and Tuomas Virtanen. Group delay function from all-pole models for musical instrument recognition. In Mitsuko Aramaki, Olivier Derrien, Richard Kronland-Martinet, and Sølvi Ystad, editors, Sound, Music, and Motion, Lecture Notes in Computer Science, pages 606–618. Springer International Publishing, 2014. doi:10.1007/978-3-319-12976-1_37. 7 cites
Group Delay Function from All-Pole Models for Musical Instrument Recognition
Abstract
In this work, the feature based on the group delay function from all-pole models (APGD) is proposed for pitched musical instrument recognition. Conventionally, the spectrum-related features take into account merely the magnitude information, whereas the phase is often overlooked due to the complications related to its interpretation. However, there is often additional information concealed in the phase, which could be beneficial for recognition. The APGD is an elegant approach to inferring phase information, which lacks of the issues related to interpreting the phase and does not require extensive parameter adjustment. Having shown applicability for speech-related problems, it is now explored in terms of instrument recognition. The evaluation is performed with various instrument sets and shows noteworthy absolute accuracy gains of up to 7% compared to the baseline mel-frequency cepstral coefficients (MFCCs) case. Combined with the MFCCs and with feature selection, APGD demonstrates superiority over the baseline with all the evaluated sets.
Keywords
Musical instrument recognition, music information retrieval, all-pole group delay feature, phase spectrum
Cites: 7 (see at Google Scholar)
Aleksandr Diment, Rajan Padmanabhan, Toni Heittola, and Tuomas Virtanen. Modified group delay feature for musical instrument recognition. In 10th International Symposium on Computer Music Multidisciplinary Research (CMMR). Marseille, France, October 2013. 33 cites
Modified Group Delay Feature for Musical Instrument Recognition
Abstract
In this work, the modified group delay feature (MODGDF) is proposed for pitched musical instrument recognition. Conventionally, the spectrum-related features used in instrument recognition take into account merely the magnitude information, whereas the phase is often overlooked due to the complications related to its interpretation. However, there is often additional information concealed in the phase, which could be beneficial for recognition. The MODGDF is a method of incorporating phase information, which lacks of the issues related to phase unwrapping. Having shown its applicability for speech-related problems, it is now explored in terms of musical instrument recognition. The evaluation is performed on separate note recordings in various instrument sets, and combined with the conventional mel frequency cepstral coefficients (MFCCs), MODGDF shows the noteworthy absolute accuracy gains of up to 5.1% compared to the baseline MFCCs case.
Keywords
Musical instrument recognition; music information retrieval; modified group delay feature; phase spectrum
Cites: 33 (see at Google Scholar)
Aleksandr Diment, Toni Heittola, and Tuomas Virtanen. Semi-supervised learning for musical instrument recognition. In 21st European Signal Processing Conference 2013 (EUSIPCO 2013). Marrakech, Morocco, September 2013. 25 cites
Semi-supervised Learning for Musical Instrument Recognition
Abstract
In this work, the semi-supervised learning (SSL) techniques are explored in the context of musical instrument recognition. The conventional supervised approaches normally rely on annotated data to train the classifier. This implies performing costly manual annotations of the training data. The SSL methods enable utilising the additional unannotated data, which is significantly easier to obtain, allowing the overall development cost maintained at the same level while notably improving the performance. The implemented classifier incorporates the Gaussian mixture model-based SSL scheme utilising the iterative EM-based algorithm, as well as the extensions facilitating a simpler convergence criteria. The evaluation is performed on a set of nine instruments while training on a dataset, in which the relative size of the labelled data is as little as 15%. It yields a noteworthy absolute performance gain of 16% compared to the performance of the initial supervised models.
Keywords
Music information retrieval; musical instrument recognition; semi-supervised learning
Cites: 25 (see at Google Scholar)
Aleksandr Diment. Semi-supervised musical instrument recognition. Master's thesis, Tampere University of Technology, Finland, 2013.
Semi-supervised musical instrument recognition
Abstract
The application areas of music information retrieval have been gaining popularity over the last decades. Musical instrument recognition is an example of a specific research topic in the field. In this thesis, semi-supervised learning techniques are explored in the context of musical instrument recognition. The conventional approaches employed for musical instrument recognition rely on annotated data, i.e. example recordings of the target instruments with associated information about the target labels in order to perform training. This implies a highly laborious and tedious work of manually annotating the collected training data. The semi-supervised methods enable incorporating additional unannotated data into training. Such data consists of merely the recordings of the instruments and is therefore significantly easier to acquire. Hence, these methods allow keeping the overall development cost at the same level while notably improving the performance of a system. The implemented musical instrument recognition system utilises the mixture model semi-supervised learning scheme in the form of two EM-based algorithms. Furthermore, upgraded versions, namely, the additional labelled data weighting and class-wise retraining, for the improved performance and convergence criteria in terms of the particular classification scenario are proposed. The evaluation is performed on sets consisting of four and ten instruments and yields the overall average recognition accuracy rates of 95.3 and 68.4%, respectively. These correspond to the absolute gains of 6.1 and 9.7% compared to the initial, purely supervised cases. Additional experiments are conducted in terms of the effects of the proposed modifications, as well as the investigation of the optimal relative labelled dataset size. In general, the obtained performance improvement is quite noteworthy, and future research directions suggest to subsequently investigate the behaviour of the implemented algorithms along with the proposed and further extended approaches.
Anssi Klapuri, Tuomas Virtanen, and Toni Heittola. Sound source separation in monaural music signals using excitation-filter model and em algorithm. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2010), 5510–5513. Dallas, Texas, USA, 2010. 43 cites
Sound source separation in monaural music signals using excitation-filter model and em algorithm
Abstract
This paper proposes a method for separating the signals of individual musical instruments from monaural musical audio. The mixture signal is modeled as a sum of the spectra of individual musical sounds which are further represented as a product of excitations and filters. The excitations are restricted to harmonic spectra and their fundamental frequencies are estimated in advance using a multipitch estimator, whereas the filters are restricted to have smooth frequency responses by modeling them as a sum of elementary functions on Mel-frequency scale. A novel expectation-maximization (EM) algorithm is proposed which jointly learns the filter responses and organizes the excitations (musical notes) to filters (instruments). In simulations, the method achieved over 5 dB SNR improvement compared to the mixture signals when separating two or three musical instruments from each other. A slight further improvement was achieved by utilizing musical properties in the initialization of the algorithm.
Keywords
Sound source separation, excitation-filter model, maximum likelihood estimation, expectation maximization
Cites: 43 (see at Google Scholar)
Toni Heittola, Anssi Klapuri, and Tuomas Virtanen. Musical instrument recognition in polyphonic audio using source-filter model for sound separation. In International Conference on Music Information Retrieval (ISMIR), 327–332. Kobe, Japan, 2009. Best paper award 200 cites
Musical Instrument Recognition in Polyphonic Audio Using Source-Filter Model for Sound Separation
Abstract
This paper proposes a novel approach to musical instrument recognition in polyphonic audio signals by using a source-filter model and an augmented non-negative matrix factorization algorithm for sound separation. The mixture signal is decomposed into a sum of spectral bases modeled as a product of excitations and filters. The excitations are restricted to harmonic spectra and their fundamental frequencies are estimated in advance using a multipitch estimator, whereas the filters are restricted to have smooth frequency responses by modeling them as a sum of elementary functions on the Mel-frequency scale. The pitch and timbre information are used in organizing individual notes into sound sources. In the recognition, Mel-frequency cepstral coefficients are used to represent the coarse shape of the power spectrum of sound sources and Gaussian mixture models are used to model instrument-conditional densities of the extracted features. The method is evaluated with polyphonic signals, randomly generated from 19 instrument classes. The recognition rate for signals having six note polyphony reaches 59%.
Keywords
Sound source separation, excitation-filter model
Awards: Best paper award
Cites: 200 (see at Google Scholar)
Tuomas Virtanen and Toni Heittola. Interpolating hidden markov model and its application to automatic instrument recognition. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2009), 49–52. Washington, DC, USA, 2009. IEEE Computer Society. URL: http://dx.doi.org/10.1109/ICASSP.2009.4959517, doi:10.1109/ICASSP.2009.4959517. 6 cites
Interpolating hidden Markov model and its application to automatic instrument recognition
Abstract
his paper proposes an interpolating extension to hidden Markov models (HMMs), which allows more accurate modeling of natural sounds sources. The model is able to produce observations from distributions which are interpolated between discrete HMM states. The model uses Gaussian mixture state emission densities, and the interpolation is implemented by introducing interpolating states in which the mixture weights, means, and variances are interpolated from the discrete HMM state densities. We propose an algorithm extended from the Baum-Welch algorithm for estimating the parameters of the interpolating model. The model was evaluated in automatic instrument classification task, where it produced systematically better recognition accuracy than a baseline HMM recognition algorithm.
Keywords
Hidden Markov models, acoustic signal processing, musical instruments, pattern classification
Cites: 6 (see at Google Scholar)
Musical Genre Recognition
Genre classification is a core MIR task, made hard by how subjective and overlapping genre definitions are. My Master's thesis tackled it with a structured approach combining timbral, rhythmic, and pitch-based features, building a musical genre recognition system that matched the best methods of its time. Listening experiments showed even humans only hit about 75% accuracy on short audio samples — a useful reality check on the task's difficulty. The thesis also explored musical instrument detection, proposing a drum detection method based on subband amplitude envelope periodicity that reached 81% accuracy, and we built a general-purpose music database with manual annotations to support it all.
- Developed a genre recognition system (MFCCs and Hidden Markov Models), achieving state-of-the-art performance ~60%
- Conducted listening experiments showing human genre recognition accuracy of ~75% on five-second samples
- Proposed a novel drum detection method based on subband amplitude envelope periodicity
- Explored automatic detection of pitched musical instruments
- Compiled a general-purpose music database with manually annotated recordings to support training and evaluation
- Contributed to the understanding of the role of timbre, rhythm, and pitch in genre classification
Toni Heittola. Automatic classification of music signals. Master's thesis, Department of Information Technology, Tampere University Of Technology, 2004. 31 cites
Automatic Classification of Music Signals
Abstract
Collections of digital music have become increasingly common over the recent years. As the amount of data increases, digital content management is becoming more important. In this thesis, we are studying content-based classification of acoustic musical signals according to their musical genre (e.g., classical, rock) and the instruments used. A listening experiment is conducted to study human abilities to recognise musical genres. This thesis covers a literature review on human musical genre recognition, state-of-the-art musical genre recognition systems, and related fields of research. In addition, a general-purpose music database consisting of recordings and their manual annotations is introduced. The theory behind the used features and classifiers is reviewed and the results from the simulations are presented. The developed musical genre recognition system uses mel-frequency cepstral coefficients to represent the time-varying magnitude spectrum of a music signal. The class-conditional feature densities are modelled with hidden Markov models. Musical instrument detection for a few pitched instruments from music signals is also studied using the same structure. Furthermore, this thesis proposes a method for the detection of drum instruments. The presence of drums is determined based on the periodicity of the amplitude envelopes of the signal at subbands. The conducted listening experiment shows that the recognition of musical genres is not a trivial task even for humans. On the average, humans are able to recognise the correct genre in 75% of cases (given five-second samples). Results also indicate that humans can do rather accurate musical genre recognition without long-term temporal features, such as rhythm. For the developed automatic recognition system, the obtained recognition accuracy for six musical genres was around 60%, which is comparable to the state-of-the-art systems. Detection accuracy of 81% was obtained with the proposed drum instrument detection method.
Cites: 31 (see at Google Scholar)
Toni Heittola and Anssi Klapuri. Locating segments with drums in music signals. In 3rd International Conference on Music Information Retrieval (ISMIR), 271–272. Paris, France, 2002. 26 cites
Locating Segments with Drums in Music Signals
Abstract
A system is described which segments musical signals according to the presence or absence of drum instruments. Two different yet approximately equally accurate approaches were taken to solve the problem. The first is based on periodicity detection in the amplitude envelopes of the signal at subbands. The band-wise periodicity estimates are aggregated into a summary autocorrelation function, the characteristics of which reveal the drums. The other mechanism applies straightforward acoustic pattern recognition with mel-frequency cepstrum coefficients as features and a Gaussian mixture model classifier. The integrated system achieves 88 % correct segmentation over a database of 28 hours of music from different musical genres. For the both methods, errors occur for borderline cases with soft percussive-like drum accompaniment, or transient-like instrumentation without drums.
Cites: 26 (see at Google Scholar)
Electroacoustics
Electroacoustics is the field that studies the conversion between electrical signals and sound waves, forming the foundation of technologies such as microphones, loudspeakers, and audio playback systems. A central component in this domain is the loudspeaker, which transforms electrical input into acoustic output. The most common type, the moving-coil loudspeaker, behaves linearly only under small signal conditions. At higher input levels, nonlinearities emerge, causing distortion that degrades audio quality.
Real-Time Adaptation of Nonlinear Loudspeaker Model Parameters
This project, conducted in collaboration with Nokia Research Center, focused on the real-time adaptation of loudspeaker model parameters using nonlinear modeling techniques. The goal was to enhance the accuracy and responsiveness of loudspeaker behavior modeling under dynamic audio playback conditions, particularly for microspeakers in mobile devices.
A continuous-time linear model was developed, extended with key nonlinearities, and then converted into a discrete-time form. An adaptive algorithm based on the LMS method was implemented to track parameter changes in real time. After two years of active involvement in the project, I transitioned into a supervisory role, guiding a Master’s thesis that continued the research.
- Developed a compact linear model for microspeakers and extended it with key nonlinearities.
- Improved accuracy of loudspeaker modeling in mobile devices.
- Advanced real-time nonlinear system identification techniques.
Juha Matikainen. Parameter adaptation in nonlinear loudspeaker models. Master's thesis, Department of Information Technology, Tampere University Of Technology, 2010.
Parameter Adaptation in Nonlinear Loudspeaker Models
Abstract
Loudspeaker is a device that converts electric input signal to acoustic output. The most common type of loudspeaker is a moving-coil transducer. The behaviour of a moving-coil transducer can be considered to be linear only when displacement of the coil-diaphragm assembly is small. When input signal level rises, nonlinearities start to cause audible distortion. In this thesis we examine microspeaker, a small loudspeaker used in mobile phones. The electro-mechanical process which converts the electrical signal into sound waves is exaplained. Based on this, we present a continuous-time, linear model of a loudspeaker mounted in a closed box. The model describes the loudspeaker's small-signal behaviour using only few parameters. We then consider the main sources of nonlinearities and how to model them. Two major sources nonlinearities are added to the continuous-time model. Then transformations from continuous-time models to discrete-time models are considered. The nonlinear model is converted to discrete-time while taking into account the properties of the microspeaker. The main purpose of this thesis is to study performance of a algorithm that finds the parameter values of the nonlinear loudspeaker model. Performance of the algorithm is compared to performance of an earlier algorithm for the linear loudspeaker model. The parameter values are found and changes in them are tracked using an adaptive signal processing method called system identification. The parameter values are updated using LMS algorithm. Since the discrete-time mechanical model of the microspeaker is based on a recursive filter, LMS algorithm for recursive filters is presented. We also review previous research related to parameter identification in linear and nonlinear loudspeaker models. Based on results from the experiments the studied algorithm is deemed to be yet incomplete. Linear parameters adapt in general quickly whereas the nonlinear parameters adapt too slowly and sometimes erroneously. The difference between the output predicted by the nonlinear loudspeaker model and the actual output of the loudspeaker (prediction error) is too high, meaning the parameters do not adapt to their true values. The model is also prone to instability. The algorithm requires further development regarding adaptation speed and prevention of instability. Other development considering initial parameter values and operation during silent moments should also be conducted in the future.